White Paper - Architecting a Scalable Real-Time Application on an SMP Platform

Contributed by | Interval Zero
Overview
When upgrading your hardware platform to a newer and more powerful CPU with more, faster cores, you expect the application to run faster. More cores should reduce the average CPU load and therefore reduce delays. In many cases, however, the application does not run faster and the CPU load is almost the same as for the older CPU. With high-end CPUs, you may even see interferences that break determinism. Why does this happen, and what can you do about it?
The answer: build for scalability. Unless an application is architected to take advantage of a multicore environment, most RTOS applications on 1-core and 4-core IPCs will perform nearly identically (contrary to the expectation that an RTOS application should scale linearly and execute 4 times faster on a 4 core IPC than it does on a 1 core IPC.) Without a scalable system, 3 of the 4 cores on the 4 core system will not be utilized. Even if the application seeks to use multiple cores, other architectural optimizations involving memory access, IO, caching strategies, data synchronization and more must be considered for the system to truly achieve optimal scalability.
While no system delivers linear scalability, you can work to achieve each application’s theoretical limit. This paper identifies the key architectural strategies that ensure the best scalability of an RTOS-based application. We will explore CPU architectures, explain why performance does not get the expected boost with newer or more powerful cores, describe how to reduce the effects of the interferences, and provide recommendations for hardware modifications to limit bottlenecks.
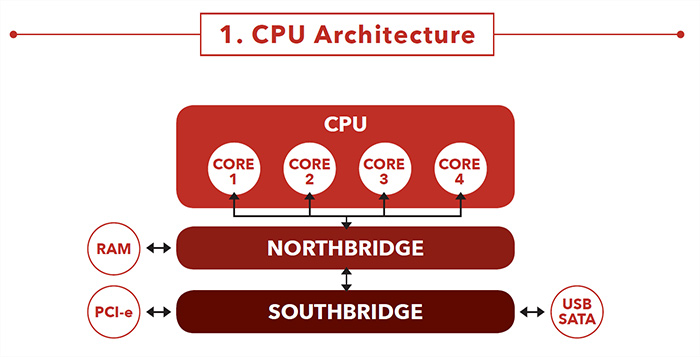
Introduction
This paper, written for RTOS users, addresses a system where both real-time and non-realtime applications run at the same time. To keep determinism in the real-time applications, they ideally should not share any hardware with the nonreal- time applications. But at the same time, it is helpful to have memory spaces and synchronization events available to both sides.
However, it is not possible to achieve both. Either you have a dedicated real-time computer but must rely on a bus protocol to exchange data with the non-real-time applications, or you have both on the same machine but they will share the CPU bus and cache. Nowadays CPU cores are much faster than memory and I/O access, so the interferences come from competition in the access of these resources.
There is another important thing to consider when using multiple cores. The different threads in an application usually share variables, so access to these variables has to be synchronized to ensure the values are consistent. The CPU will do this automatically if it is not handled in the code, but as the CPU does not know the whole program, it will not handle it optimally and this will create many delays. These delays are the reason that an application will not necessarily run faster on two cores than on one.
This paper will first examine the CPU architecture relating to caches, memory and I/O access. Then we will explain how threads interact and how program design can help improve performances with multiple cores. Finally, we will give examples of practical problems and what can be done to solve or minimize them.
Most of the technical information in this paper is based on the excellent paper What Every Programmer Should Know About Memory by Ulrich Drepper at Red Hat. We recommend reading that paper if you have the time.

Download this White Paper Today
The content & opinions in this article are the author’s and do not necessarily represent the views of ManufacturingTomorrow
Comments (0)
This post does not have any comments. Be the first to leave a comment below.
Featured Product

